Appearance
Data Buckets
A Data Bucket is used for general, unstructured storage of data online. This is basically a folder in S3 format that is commonly used to store and access large datasets. Most cloud vendors offer S3 data buckets as a general storage data mechanism. The platform supports buckets from vendors such as Azure, Google and Amazon Web Services. They are particularly popular for Data Science applications.
Data Buckets allow you to use your external datasets inside a workspace. A data bucket attached to a workspace is automatically mounted as a folder to the container's filesystem.
As for the other types of resources, data buckets are first imported to the platform such that they become available when creating or updating the configuration of a workspace.
View Data Buckets
Data Buckets used in the project are being displayed. You may filter those in use.
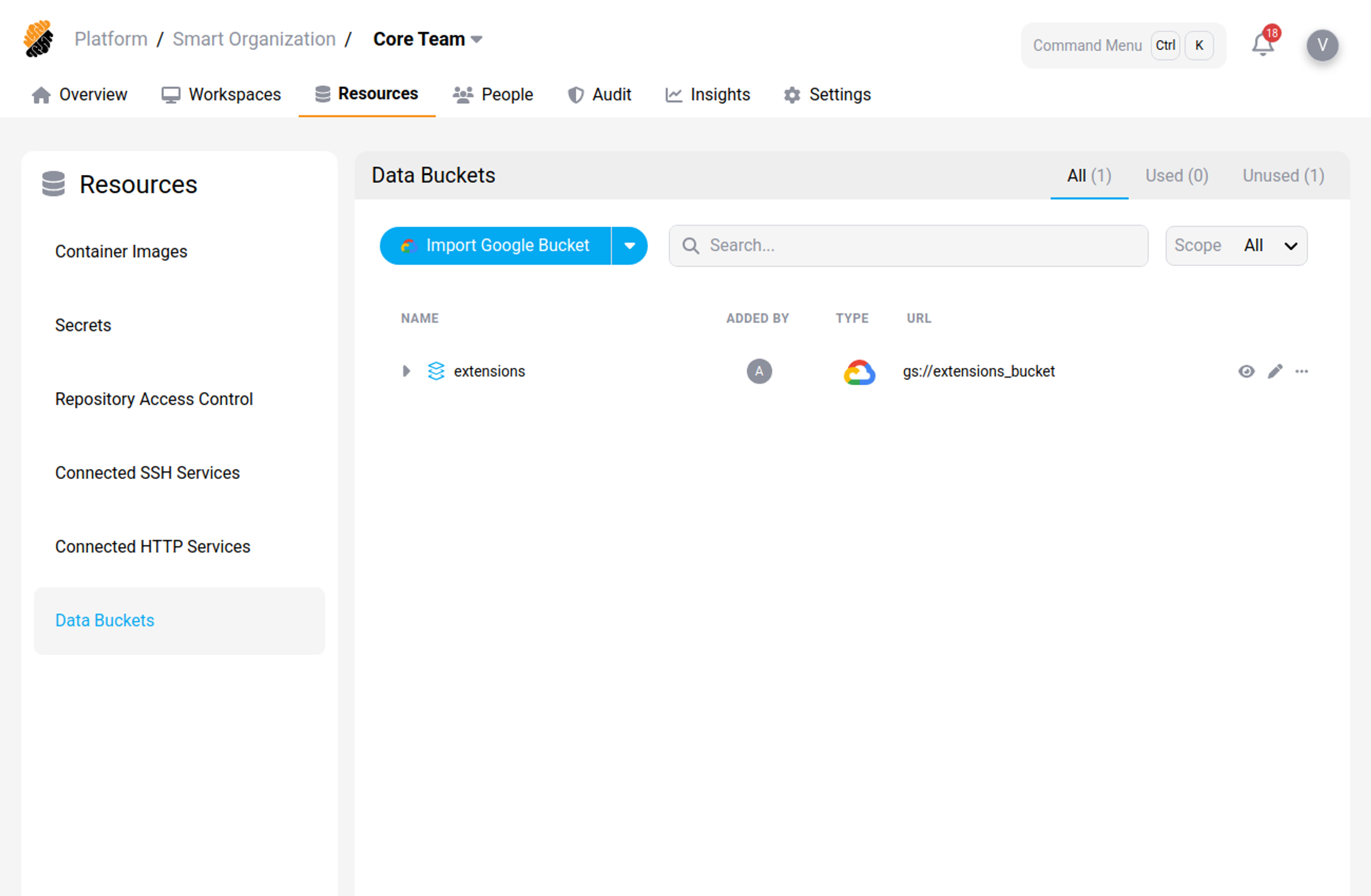 Data Buckets List
Data Buckets List
A Data Bucket is defined by the following characteristics:
- Basic information: Information such as name, the user who added it, service provider (Google, Amazon or Microsoft) and URL.
- Class Level: This option defines the visibility for the container based on the user's permissions.
- Permissions: This option lets you define access to a data bucket as read or read and write.
- Asset Information: This option allows for providing a description of the data bucket.
The platform provides a mechanism to create versions of buckets. A new version is created when data is uploaded to a bucket from a workspace (with write access). By clicking on a bucket you can see a list of versions followed by basic details (creation date, size, status, connections) as well as its content by clicking on the book icon.
Import a Data Bucket Permission: Resources::Manage
You can import a bucket by pressing the "Import Bucket" button. Make sure to select the correct provider of your bucket (Google, Amazon or Microsoft).
You will need to enter the following information:
- Name, a name to identify the data bucket, and a
- Bucket URL that points to the Cloud provider's storage location.
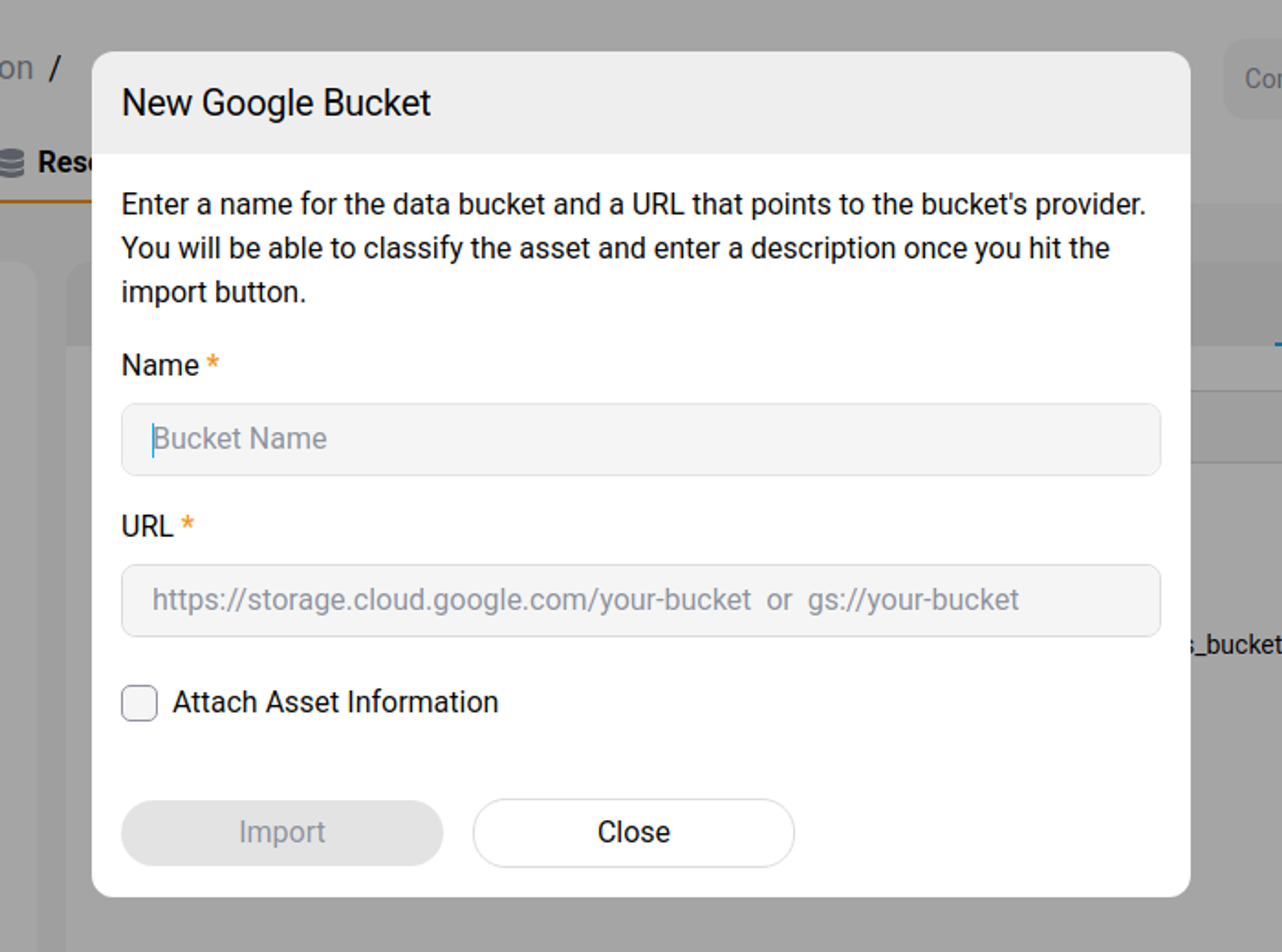 Import Data Buckets Section
Import Data Buckets Section
INFO
When importing Amazon buckets, you need to specify its region to optimize the data access performance.